
Drug discovery and development are both time and resource intensive. The discovery process would be more effective if all compounds were screened across all possible targets. However, the required time and money for this type of full and exhaustive experimentation would be prohibitive. How can machine learning models be used to predict screening results? How can active learning algorithms be used to efficiently select which experiments to perform in order to build those models?
The Problem with Reductionism
The theory of scientific reductionism is that systems or processes can be broken into smaller, independent components, which simplifies this system or process. However, this is often seen as oversimplification leading to a view of that system being distorted. If you take, for example, individual components of a car, like the brakes, air conditioner, or radio, you realize the interdependency of these modules. A car steering wheel might have radio controls or active cruise control, which also uses the brakes. This same reductionist approach was applied towards biology, where individual aspects or parts were broken down to the simplest, most basic physical mechanisms that are in operation. Similar to the example of the steering wheel, the human body has many interconnected and interdependent systems that run in concert. Cells, organs, and organisms are complex systems where the whole is greater than the sum of the parts.
The Systems Biology Approach
In the 1980s there was a shift to a more holistic view of cells, organs, and organisms, which led to the field of Systems Biology. This approach focused on understanding the larger picture by putting its pieces together, as a system, which is in contrast to the previously described reductionist biology approach, which involves taking the individual pieces apart. However, there is a natural limit to the number of experiments that can be performed. Instead of doing all experiments, researchers built predictive models from a smaller number of experiments, which were validated. This predictive approach is quite problematic since the model itself cannot be validated; only specific predictions can be validated.
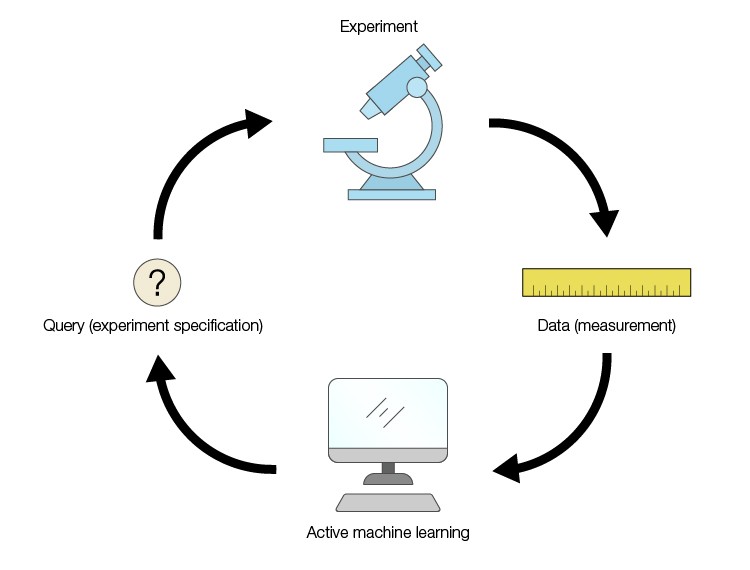
Using Active Learning
Imagine trying to screen 96 drug compounds on 96 targets without doing experiments across all drug compounds and targets. This can be achieved through active learning, which is a special type of machine learning, where a learning algorithm is able to interactively query the user to obtain the desired outputs at new data points. Active learning can recommend the number of type(s) of experiments to conduct to achieve a desired result, in this case finding drug compounds that affect a target. It does this by learning a relationship between the contextual variable (size of the data set to use) and the reliability of the final score achieved. This means that by training the model on a subset of experiments, it can extrapolate the performance of the model on the full experimental data. Researchers who employ this method can reduce the overall number of experiments conducted, based on the model, which prioritizes the highest value experiments. Consequently, a researcher may only do a small fraction of the 96 factorial experiments to find the compounds that have the desired outcome on a given target.
Labeling Data
For most machine learning tasks, large amounts of labeled data are needed for model training. However, the process of labeling data can be extremely time consuming and/or expensive. Labeled data are a group of samples (compounds or targets) that have been tagged with one or more labels. After obtaining a labeled dataset, machine learning models can be applied to the data so that new, unlabeled data can be presented to the model and a likely label can be guessed or predicted for that piece of unlabeled data. Using machine learning models, active learning can help identify difficult data points and lead a scientist to labeling those specific data points or experiments. Effectively, the model determines which data or variables are most critical to be labeled, saving valuable time and money.
Automated Science
In the not too distant future, active machine learning will be used to guide experimentation in several areas of research, including drug discovery. Just like for self-driving cars, the human role will be deciding where to go, not how to get there. Active learning, like several other tools/technologies, has its limitations. It has been shown to be highly vulnerable to biases, in particular because they are at risk of self-indulging in initial beliefs derived from the patterns identified by a model trained on a fairly small dataset. However, as scientists, we must embrace new technologies in order to help accelerate research, which active learning can help achieve.


